저번 시간에 이어서 내 최애 유튜버 슈카월드 유튜브 채널에 대해 분석해보겠다. 아래 코드를 돌리면 슈카월드 채널에 있는 모든 동여상의 제목과 해당되는 Video ID값을 구할 수 있을 것이다. Video ID값이 필요한 이유는 이게 있어야 각 동영상별 좋아요 수, 조회 수 등 상세 데이터 지표를 뽑을 수 있기 때문이다. 내가 구한 슈카월드 채널의 동영상 수는 665개로 확인되었다.
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from oauth2client.tools import argparser
DEVELOPER_KEY = "~" #유튜브 API 키 값
YOUTUBE_API_SERVICE_NAME = "youtube"
YOUTUBE_API_VERSION = "v3"
youtube = build(YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION,developerKey=DEVELOPER_KEY)
search_response = youtube.search().list(
q = "슈카월드",
order = "relevance",
part = "snippet",
maxResults = 50
).execute()
channel_id=search_response['items'][0]['id']['channelId']
playlists=youtube.playlists().list(
channelId= channel_id,
part = "snippet",
maxResults=20
).execute()
import pandas as pd
playlist_titles=[]
playlist_ids=[]
for i in playlists['items']:
playlist_titles.append(i['snippet']['title'])
playlist_ids.append(i['id'])
df=pd.DataFrame([playlist_titles,playlist_ids]).T
df.columns=['playlist','playlist_id']
video_ids=[]
video_titles=[]
video_dates=[]
for av in df['playlist_id']:
playlist_videos=youtube.playlistItems().list(
playlistId= av,
part = "snippet",
maxResults=50,
)
while playlist_videos:
playlistitems_list_response = playlist_videos.execute()
# Print information about each video.
for playlist_item in playlistitems_list_response["items"]:
title = playlist_item["snippet"]["title"]
video_id = playlist_item["snippet"]["resourceId"]["videoId"]
video_ids.append(video_id)
video_titles.append(title)
playlist_videos = youtube.playlistItems().list_next(
playlist_videos, playlistitems_list_response)
video_df=pd.DataFrame()
video_df['Title']=video_titles
video_df['Video Id']=video_ids
슈카월드 동영상별 보고자 하는 데이터는 다음과 같다. 영상 카테고리, 조회 수, 좋아요 수, 싫어요 수, 댓글 수, 영상 길이, 영상 제목이다. 코드는 Youtube Api V3 페이지에서 설명하고 있는 내용을 그대로 따왔다. 반복문을 사용해서 665개 영상 ID값을 기준으로 데이터를 추출해봤다.
import re
category_id=[]
views=[]
likes=[]
dislikes=[]
comments=[]
mins =[]
seconds=[]
title=[]
ids=[]
for i in range(len(video_df)):
request = youtube.videos().list(
part="snippet,contentDetails,statistics",
id=video_df['Video Id'][i]
)
response = request.execute()
if response['items']==[]:
title.append("-")
ids.append("-")
category_id.append("-")
views.append("-")
likes.append("-")
dislikes.append("-")
comments.append("-")
else:
title.append(response['items'][0]['snippet']['title'])
ids.append(video_df['Video Id'][i])
category_id.append(response['items'][0]['snippet']['categoryId'])
views.append(response['items'][0]['statistics']['viewCount'])
likes.append(response['items'][0]['statistics']['likeCount'])
dislikes.append(response['items'][0]['statistics']['dislikeCount'])
comments.append(response['items'][0]['statistics']['commentCount'])
suka_df=pd.DataFrame([title,ids,category_id,views,likes,dislikes,comments]).T
suka_df.columns=['title','ids','category_id','views','likes','dislikes','comments']위 코드의 결과 Suka_df의 값은 다음과 같이 나올 것이다.
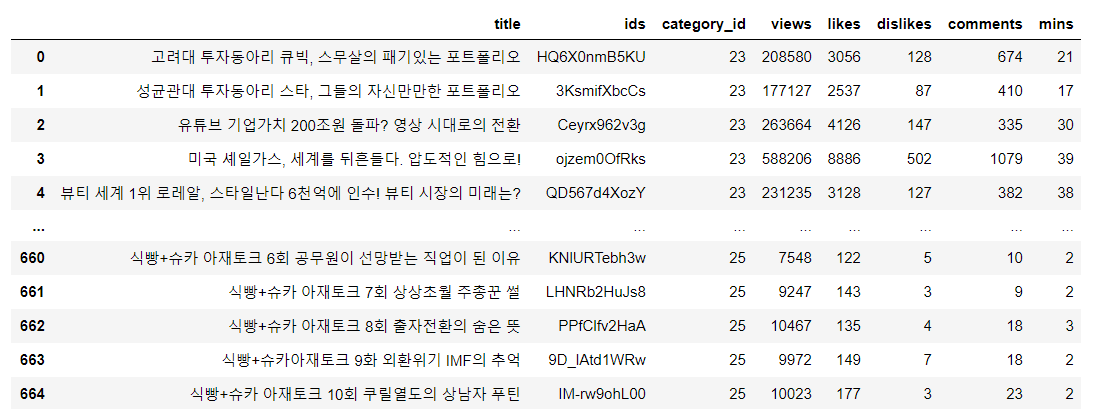
슈카월드 조회수 Top 5 영상
중복 값을 제거하고, 데이터 값이 추출 안된 행도 제거하는 전처리가 필요하다. 그다음에 조회 수 값으로 내림차순 정렬을 하면 어떤 영상이 가장 높은 조회 수를 기록했는지 알 수 있다. 역시 주총꾼 썰이 두번째로 가장 높은 조회수를 기록했다. 지금의 슈카월드가 있는데 가장 큰 기여를 한 영상이 아닌가 생각이 든다. 쿠팡 영상도 내가 한 3번이나 다시 재생한 정말로 유익한 콘텐츠 였다. 이렇게 다시 보니까 top 5 영상을 다시 보고 싶기도 하다.
suka=suka_df[suka_df['views']!='-']
suka['views']=suka['views'].astype(int)
suka=suka.drop_duplicates(['title'])
suka=suka.sort_values(by='views',ascending=False)
suka.head(5)
이번 시간에 간단히 슈카월드 영상의 상세 데이터를 가져와 봤다. 이 데이터를 기반으로 다음 시간에 더 상세한 분석을 해보도록 하겠다.
'문송충의 코딩하기 > 파이썬 데이터 분석' 카테고리의 다른 글
| 공공데이터 API 활용해서 2019년 코스피 배당주 리스트 가져오기 With Python (0) | 2020.09.29 |
|---|---|
| 공공데이터 Open API를 활용한 국내 코로나 확진자 수 가져오기 feat 파이썬 (0) | 2020.09.01 |
| 슈카월드 유튜브 채널 파이썬으로 분석하기 (0) | 2020.08.19 |
| 파이썬으로 유튜브 슈카월드 검색 결과 가져오기 (0) | 2020.08.14 |
| 파이썬으로 국내 성, 연령별 코로나 확진자 수 크롤링 (0) | 2020.07.27 |




댓글